UTS元数据(ClickHouse)日志查询的终极优化方案
UTS-胡义勇 2023/11/28
问题背景
UTS中的元数据日志,威胁日志,敏感数据日志,存储于ClickHouse数据库中。在日常的使用中,日志数据量级基本在10亿级左右。界面的日志展示通常以分页展示,然而在数据量级过亿后,当点击最后一页,进行数据查询时,基本无响应或等待非常久(基本是nginx主动中断会话连接)导致无数据返回,这就是数据库查询中经典的深度分页查询问题。在UTS数据库表设计中,原始设计并不存在这唯一字段和自增字段的设计,另外界面查询需求中的条件查询,字段任意,数据库中并没有相对的索引优化。当数据过亿以后,就算是前几页的响应也会变的很慢(基本在4秒左右,甚至以上),如果携带查询条件后,整体扫描的数据大小基本在20G左右。ck数据库引擎需要将这20G左右的数据进行解压,加载入内存,扫描数据,十分消耗机器的性能和内存,尤其在流量大的场景中,class在忙于流量处理和入库日志,需要占据大量的核和消耗大量的内存,此时的日志首页读取也将变得十分缓慢。在AMD设备中,这种现象变得尤为明显,基本可以称之为不可用(一个基本的查询均被x86慢1到2倍左右)。
问题定义
深度分页查询:在数据查询中,执行执行分页查询,可以使用LIMIT和OFFSET子句。
OFFSET子句用于跳过查询返回的前N行。
将OFFSET变大
语句1:选择所有列,offset为1000, limit为10

语句2:选择所有列,offset为10000000, limit为10

语句3:选择所有列,offset为20000000, limit为10

语句4:选择所有列,offset为28819800, limit为10(最后10条)

时间趋势
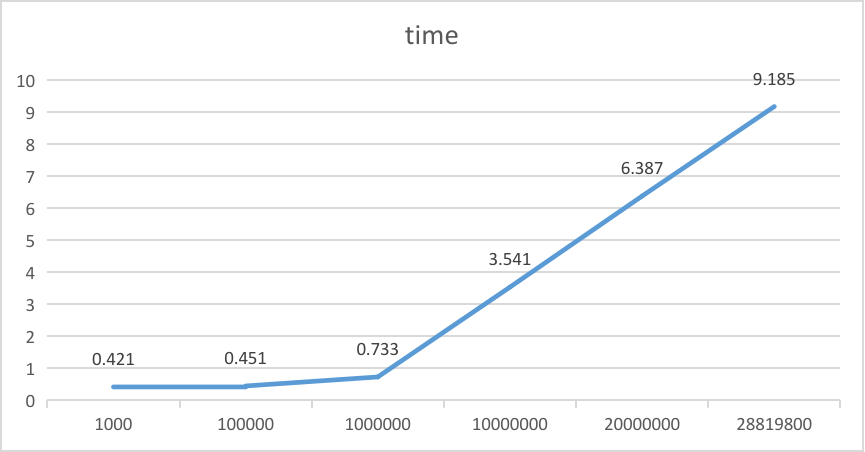
扫描的数据行数趋势
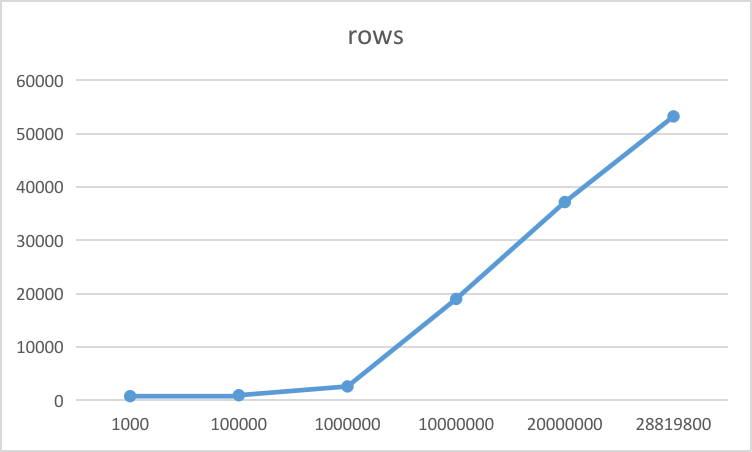
从上述语句执行实验结果发现:在查询结果集数量一定的情况下,查询时间和查询深度成正比。
深度分页效率低原因
limit m,n查询过程是数据库的服务层的执行器调用存储引擎从磁盘中读取m+n条记录到服务层,然后服务层根据offset丢掉前m条,保留第【m,m+n】n条结果,并返回给客户端返回,从磁盘中读取m+n条数据是整个查询过程中耗时的操作,理论上分析limitm,n 方式查询m条数所用耗时和直接查询m+n数据时间应该接近,没有明显的时间差距。
常用方案
子查询优化
前提条件:维持目前数据库的设置不变
优化原理:使用嵌套查询,在内层循环中只取索引列字段,确定深度分页的偏移量,此时不需要回表,在外层查询中使用索引筛偏移量之后的要查询结果集,总体来说是通过减少回表查询记录数,提高查询效率。
select * from storage_session where sid in (select sid from storage_ssesion where timestamp >= 1701057469 and timestamp <= 1701057469 msgtype=12 order by timestamp desc limit 10000,10);

注意:需要sid唯一,且sid需要设置为索引
实际执行效果
语句1: 选择所有数据列, ofsset为10000000,limit为10
select * from storage_session prewhere sid global in (select sid from storage_session prewhere msgtype = 12 order by timestamp desc limit 10 offset 10000000) order by timestamp desc

语句2:只选取1列, ofsset为10000000,limit为10
select sid from storage_session prewhere sid global in (select sid from storage_session prewhere msgtype = 12 order by timestamp desc limit 10 offset 10000000) order by timestamp desc

语句3:选择所有数据列, ofsset为28819800,limit为10(最后一页的10条)
select * from storage_session prewhere sid global in (select sid from storage_session prewhere msgtype = 12 order by timestamp desc limit 10 offset 28819800) order by timestamp desc
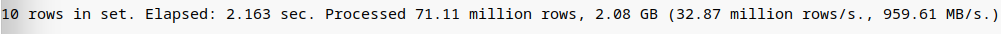
结论:从语句1和语句2可以看出,外层查询语句选择多少列,并不影响数据扫描的行数和数据量的大小,且确实能加速查询的速度。从语句1和语句3对比可以看出,随着数据偏移量从1千万增加到将近3千万,对查询速度有所影响但相比原始语句,影响的程度要相对更小。需要注意的是内层查询语句存在内存排序问题,尤其当子查询结果数量很大的时候,内存排序也很消耗资源,可能依然会引起慢查询,需要考虑进一步优化。
inner join优化
前提条件:维持目前数据库的设置不变
优化原理:通过减少回表记录数量提高查询效率
select e1.* from storage_session inner join (select sid from storage_session where timestamp >= 1701057469 and timestamp <= 1701057469 and msgtype=12 order by timestamp desc limit 10000,10) as e2 on e2.sid = e1.sid;

注意:需要sid唯一,且sid需要设置为索引
实际执行效果
语句1:选择所有数据列, ofsset为10000000,limit为10
select * from storage_session as e1 inner join (select sid from storage_session prewhere msgtype=12 order by timestamp desc limit 10000000,10) as e2 on e2.sid=e1.sid;

语句2:只选取1列, ofsset为10000000,limit为10
select sid from storage_session as e1 inner join (select sid from storage_session prewhere msgtype=12 order by timestamp desc limit 10000000,10) as e2 on e2.sid=e1.sid;
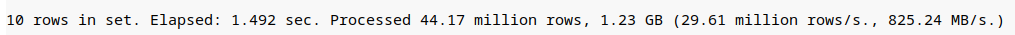
语句3:选择所有数据列, ofsset为28819800,limit为10(最后一页的10条)
select * from storage_session as e1 inner join (select sid from storage_session prewhere msgtype=12 order by timestamp desc limit 28819800,10) as e2 on e2.sid=e1.sid;
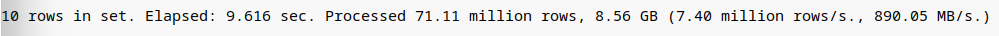
结论:从上面执行实验可以看出选择所有数据列的语句1和语句3将会将所有列的数据进行扫描,总共大小达到7.71GB,而只选择1列语句2只会加载一列,和子查询优化中的语句2一样。而在我们的应用场景中,往往需要加载多列,这以为着,此方案并不能达到我们想要优化的效果。
游标记录优化
优化原理:存在自增id(sa_id), 在非第一次查询之后,查询时,记录上一次读取的最后一条的自增id。
select * from storage_session where sa_id < 1701057469 and msgtype=12 order by timestamp desc limit 10;
注意:在查询过程,不能进行跳页查看,只能前后翻页
结论:此方案,尽管效果会是最佳的,但是并不符合我们的业务场景。首先我们系统中不存在自增ID,其次此方案不支持跳页查询,只支持前后翻页,并不能满足我们目前系统的业务场景。
调优方案
在常用方案这一节中,我们在不对现有数据库环境进行改变或调优的情况下,使用常用方案在我们系统(数据库中storage_session具有28820382条数据)进行了实际执行实验。实验结果表明,使用子查询优化方案,更符合我们系统。但子查询方案仍然存在着当子查询结果数量很大的时候,内存排序也很消耗资源,可能依然会引起慢查询,因此需要考虑进一步优化。
时间尺度放缩
减少子查询结果集合大小,才能从彻底解决子查询方案中子查询结果数量很大的时候,可能仍然将导致慢查询的问题。基于我们系统在查询时,时间范围是必要条件,因此我们可以从时间尺度放缩方面进行优化。
数据背景
首先我们来简单了解下,ClickHouse的数据写入过程。数据写入的第一步是生成分区目录,伴随着每一批数据的写入,都会生成一个新的分区目录。在后续的某一时刻,属于相同分区的目录会依照规则合并到一起;接着按照index_graunlarity索引粒度,会分别生成primary.idx一级索引(如果声明了二级索引,还会创建二级索引文件)、每一列字段的.mrk数据标记和.bin压缩数据文件。其中索引和标记区间是对齐的,而标记与压缩块则根据区间数据大小的不同,会生成多对一,一对一和一对多三种关系。
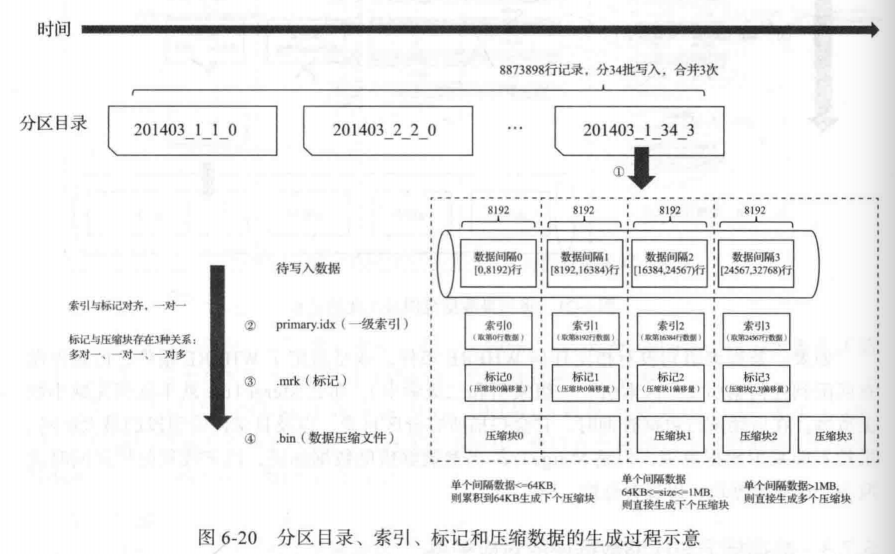
我们系统中并没有特意设置index_granularity的大小,所以基本取默认值8192。因此每一个数据压缩块存8192行数据。系统中的各个数据表的建表语句中均使用了PARTITION BY toYYYYMMDD(timestamp),因此数据是按天分区的。结合系统的特点,如果可以尽可能的将时间尺度缩小,首先可以减小子查询的结果集合大小,其次能够扫描的数据分区数减少。
时间模型
假设原始的查询语句1(选择所有列,设置起始时间为2020-11-01 17:40:59 结束时间为 2023-11-27 17:40:48, ofsset为28819800,limit为10(最后一页的10条))如下:
select * from storage_session prewhere sid global in (select sid from storage_session prewhere timestamp >= 1604223659 and timestamp <= 1701078048 msgtype = 12 order by timestamp desc limit 10 offset 28819800) order by timestamp desc
假设此段时间内具有的数据量为28819882条数据。因此可以建立时间模型如下:

由于我们系统的查询业务是根据时间倒序排列。因此可以定义end_time为坐标0点。
我们只需要找到里offset点最近的时间点和离offset+limit点最近的时间点,即可大幅度的降低数据查询结果。那么问题就变成了,如何快速的根据offset和offset+limit这两个偏移点快速的定位两个时间点的问题。
我们知道根据条件查询count是非常快的,因为clickhouse对每个表的数据量,在底层文件中提供了预数据。因此自然而然,我们可以使用基于时间段的count数和基准设计一套二分算法来定位这两个时间点,从而达到快速放缩时间尺度的目的,减少子查询需要查询的数据量,提升查询速度。
重新将坐标轴按照习惯性思维逆转,定义offset的点为loffset, offset+limit点为roffset
算法如下:
offset = (page - 1) * page_count # 计算偏移
limit = page_count # 获取每页数据数据
loffset = count - offset # 小端计算法
roffset = count - offset - limit
roffset = roffset if roffset > 0 else 0
max_offset = 5000 # 允许的最大偏移量
ltime = start_time # 初始化左端
rtime = end_time # 初始化右端
lcount = 0 # 记录左端的记录数量
rcount = 0 # 记录右端的记录数量
mtime = 0 # 记录靠近偏移的时刻
mcount = 0 # 记录偏移时刻的数量
deep_page_enable = offset > 10000 # 如果偏移大于8192,即一个分区granurity的大小则判定是深度分页场景,则启用时间缩放和数据量大于10万的时候,使用深度分页策略
if deep_page_enable or use_metiria: # 如果是场景1(首页)可以直接使用时间放缩,如果是场景2(带条件)必须是深度分页的时候才能启用
# 先找中间时间点
lfcount = 0
while True:
mtime = int((rtime+ltime)/2)
if mtime == ltime or mtime == rtime:
if is_debug:
write_log("时间归一中断")
break
is_start = False
if ltime != start_time:
is_start = True
time_cq = self.get_time_cq(ltime, mtime, is_start=is_start)
count_cq = CQ(time_cq) & param_cq
mcount = self.base_count(count_table, count_cq, use_metiria)
if is_debug:
write_log("中点逼近:{} {} {}".format(mtime, ltime, rtime))
lfcount = lcount+mcount
if is_debug:
write_log("中点逼近数量: {} {} {}".format(lfcount, roffset, loffset))
if lfcount < roffset:
ltime = mtime
lcount = lfcount
elif lfcount > loffset: # 如果落在右侧则缩短右侧时间
rtime = mtime
rcount = lfcount
else:
if is_debug:
write_log("中点逼近落在区间上")
break
if (lfcount > loffset and lfcount -loffset < max_offset) or (lcount < roffset and roffset-lcount < max_offset):
if is_debug:
write_log("时间中点结束")
break
mmcount = lfcount # 目前中点的落脚点
if is_debug:
write_log("lcount:{} begin_time:{} ltime:{} rtime:{} end_time: {}".format(lcount, start_time,ltime, rtime, end_time))
write_log("中点逼近结束数量: {} {} {}".format(lcount, roffset, loffset))
write_log("中点信息为:mmcount:{} mtime:{}".format(mmcount, mtime))
# 查找左边时间点,将时间进一步逼近
num = 0
lrtime = mtime
if mmcount > roffset and roffset > 0 and (mmcount - roffset > max_offset):
while True: lmtime = int((lrtime+ltime)/2)
if lmtime == ltime or lmtime == lrtime:
break is_start = False
if lcount != 0:
is_start = True
time_cq = self.get_time_cq(ltime, lrtime, is_start=is_start)
count_cq = CQ(time_cq) & param_cq
mcount = self.base_count(count_table, count_cq, use_metiria)
lfcount = lcount+mcount
if is_debug:
write_log("左端逼近:{} {} {}".format(lmtime, ltime, lrtime))
write_log("左端逼近数量: {} {} {}".format(lfcount, roffset, loffset))
if lfcount < roffset:
ltime = lmtime
lcount = lfcount
elif lfcount > roffset:
lrtime = lmtime
else:
if is_debug:
write_log("左端逼近落在点上")
break
if roffset -lcount < max_offset:
if is_debug:
write_log("时间中断:{} {}".format(offset, lcount))
break
# 查找右边时间点,将右边时间进一步逼近
if abs(mmcount -loffset) > max_offset or rtime == end_time or abs(rcount-loffset) > max_offset: # 中点超过了设置的范围,将右端点的时间进行逼近或者右边界没有被调整过,需要进行调整, 或者右端点过远也需要被调整
if is_debug:
write_log("左端信息:左端点 {} 左端边界时间点 {}".format(lcount, ltime))
write_log("开始右边逼近:中点 {} 中点时间点 {} 右边界时间点 {}".format(mmcount, mtime, rtime))
if mmcount < loffset: # 如果中点在loffset左边
rltime = mtime
rlcount = mmcount
else: # 如果中点在loffset右边
rltime = ltime # 将左端点设置为起始点
rlcount = lcount
rtime = mtime # 将右端点设置为中点
rcount = mmcount
while True:
rmtime = int((rltime+rtime)/2)
if rmtime == rltime or rmtime == rtime:
if is_debug:
write_log("右端时间归一")
break
is_start = False
if rltime != start_time:
is_start = True
time_cq = self.get_time_cq(rltime, rmtime, is_start=is_start)
count_cq = CQ(time_cq) & param_cq
mcount = self.base_count(count_table, count_cq, use_metiria)
rmcount = rlcount+mcount
if is_debug:
write_log("右端逼近: rmtime {} rltime {} rtime {}".format(rmtime, rltime, rtime))
write_log("右端逼近数量: 中点数量 {} 左边界 {} 右边界 {}".format(rmcount, roffset, loffset))
if rmcount < loffset:
rltime = rmtime
rlcount = rmcount
elif rmcount > loffset:
rtime = rmtime
rcount = rmcount
else:
if is_debug:
write_log("右端逼近落在点上")
break
if rmcount -loffset < max_offset and rmcount > loffset:
if is_debug:
write_log("时间中断:{} {}".format(loffset, rmcount))
break
if is_debug:
write_log("最终右端数量为: 统计量{}".format(rcount))
if rcount == 0:
time_cq = self.get_time_cq(ltime, rtime, is_start=True)
count_cq = CQ(time_cq) & param_cq
jcount = self.base_count(count_table, count_cq, use_metiria)
rcount = lcount+jcount
if is_debug:
write_log("最终右端数量为: 从右端查询计算量{}".format(rcount))
if ltime == rtime: # 中点归一
time_cq = self.get_time_cq(ltime, is_equal_start=True)
cq = CQ(time_cq) & param_cq
jcount = self.base_count(count_table, cq, use_metiria)
if is_debug:
write_log("最终当前时间数量为: 从查询计算量{}".format(jcount))
if roffset == 0:
offset = jcount-loffset
else:
offset = roffset
else:
offset = rcount - loffset
is_start = False
if ltime != start_time:
is_start = True
time_cq = self.get_time_cq(ltime,rtime, is_start=is_start)
cq = CQ(time_cq) & param_cq
算法中self.get_time_cq为构造时间条件函数, is_start为True时,将会设置start_time<ltime, is_end为True时,将会设置end_time<rtime,算法中对已经查询过的时间段的count数进行了累加,避免重复计算,导致性能损失。这会随着算法层次的深入,查询count的速度越来越快。
注意在我们系统中可能同一个时间点同一条件的数量可能会超过limit的数量,因此会产生offset和offset+limit在同一个时间点上的问题,这可以通过设置合适的冗余量max_offset来调整时间的偏移,来解决这个问题。
通过上面的优化手段,基本可以将查询时间得到大幅度的提升。然而二分法,会让count查询变得非常多,此查询的消耗有累加效应,尤其是当数据量过亿的时候,每次count查询所需要的时间也是仍然是很大的。
物化视图
count查询的累加效应在数据量超过5个亿的时候,变得尤为突出。因此如何加速count的查询速度,将是整个优化过程中的新的问题。我们的系统的业务主要为存储全流量相关日志,因此可以假设数据分布为均匀分布,因此可以认为在每一个时间点产生的数据量是一致的。且我们系统的数据设置了定期或当数据存储达到数据盘的80%的时候将会将旧的分区进行删除的相关机制。因此我们可以将业务首页查询的条件的count数预先建立视图并物化,以此来加速count的查询速度。
例如我们uts的日志count视图可以如下:
create materialized view if not exists uts.{table_name}_view \
to uts.{table_name}_view_target \
as \
select \
msgtype, \
timestamp, \
count(msgtype) as cnt \
from \
uts.{table_name} \
group by
msgtype, \
timestamp
系统中的时间是秒级的,每一个表的msgtype不会存在太多个。因此这里的数据量将维持在十万级,且只有三列,占用的空间很小。从而可以加速count的查询速度,优化查询体验。后续在查询count时,只需要执行:
select sum(cnt) from uts.{table_name}_view where timestamp >= 1604223659 and timestamp <= 1701078048 msgtype = 12;
尽管数据分布是假设为均匀分布,时间点是均匀的,但整个查询效果却在数据时间分布越稀疏的情况下效果越好。
结果纠偏
由于我们uts中的业务表中不存在唯一字段,我们选择的sid也并不是唯一字段(http多事务),因此如下查询语句,在子条件查询中查出来的子集结果将会存在重复结果。
select * from storage_session prewhere sid global in (select sid from storage_session prewhere msgtype = 12 order by timestamp desc limit 10 offset 100) order by timestamp desc
上述查询出的结果的数量将不再是limit条,此时需要对数据进行纠偏处理。查询出的结果存在以下三种情况:
情况1:重复结果在头部
情况2:重复结果在尾部
情况3:子查询中的sid全是重复的
对于情况1和情况2,我们使用序列匹配算法来获取正确的数据序列。对于情况3,我们只能将子查询语句变换为下面语句查询,这将会导致一些时间损耗,但由于前面的时间放缩算法,这里的损耗将比之前变得更可控,更小,这是可以接受的。
实验结果
在x86中进行实验,x86数据库中有16个亿,在默认条件(首页)和带查询条件这两个场景中,进行查询前三页和最后三页的数据,并记录其响应的实验。
场景1:默认条件(首页)
优化前
前三页的响应结果
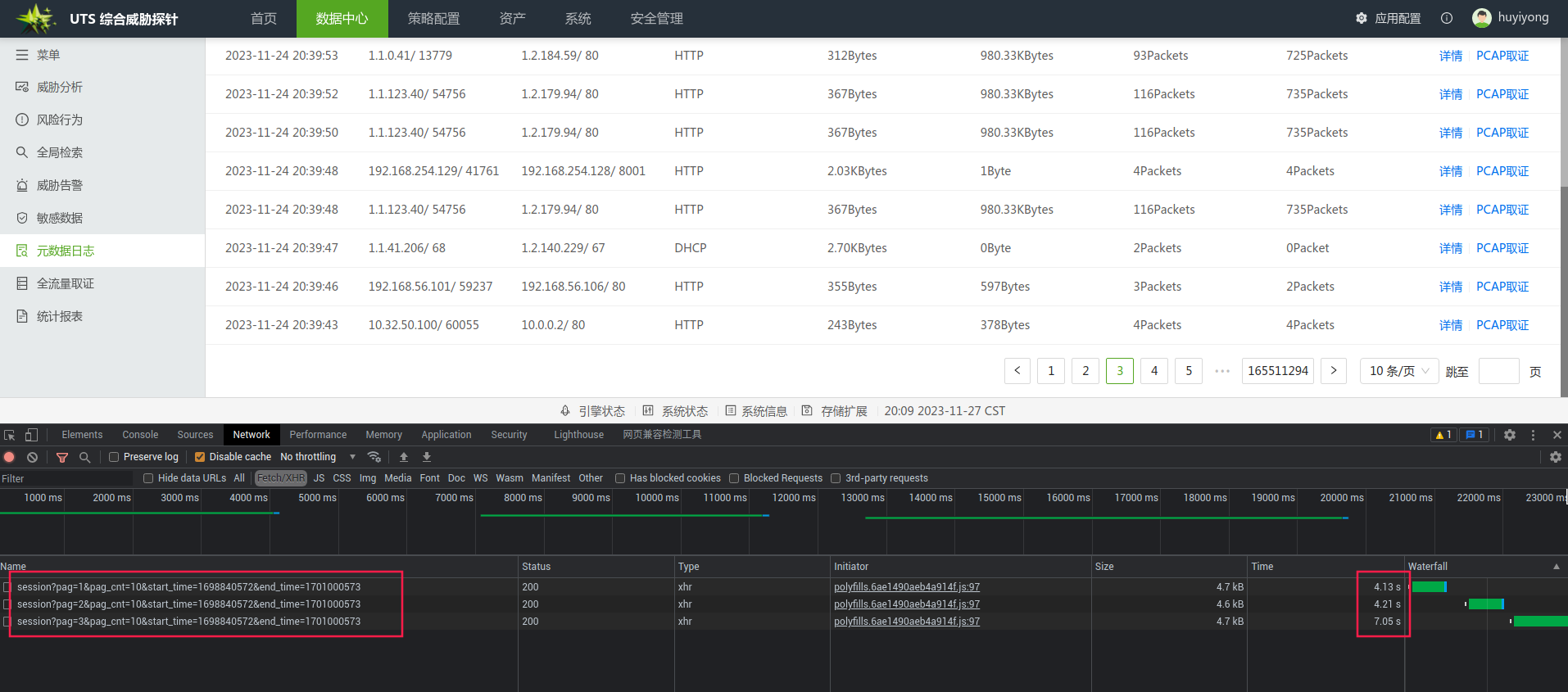
后三页的响应结果:等待了6分钟没有获取到结果,最后被放弃了这个查询。几乎不可能查询
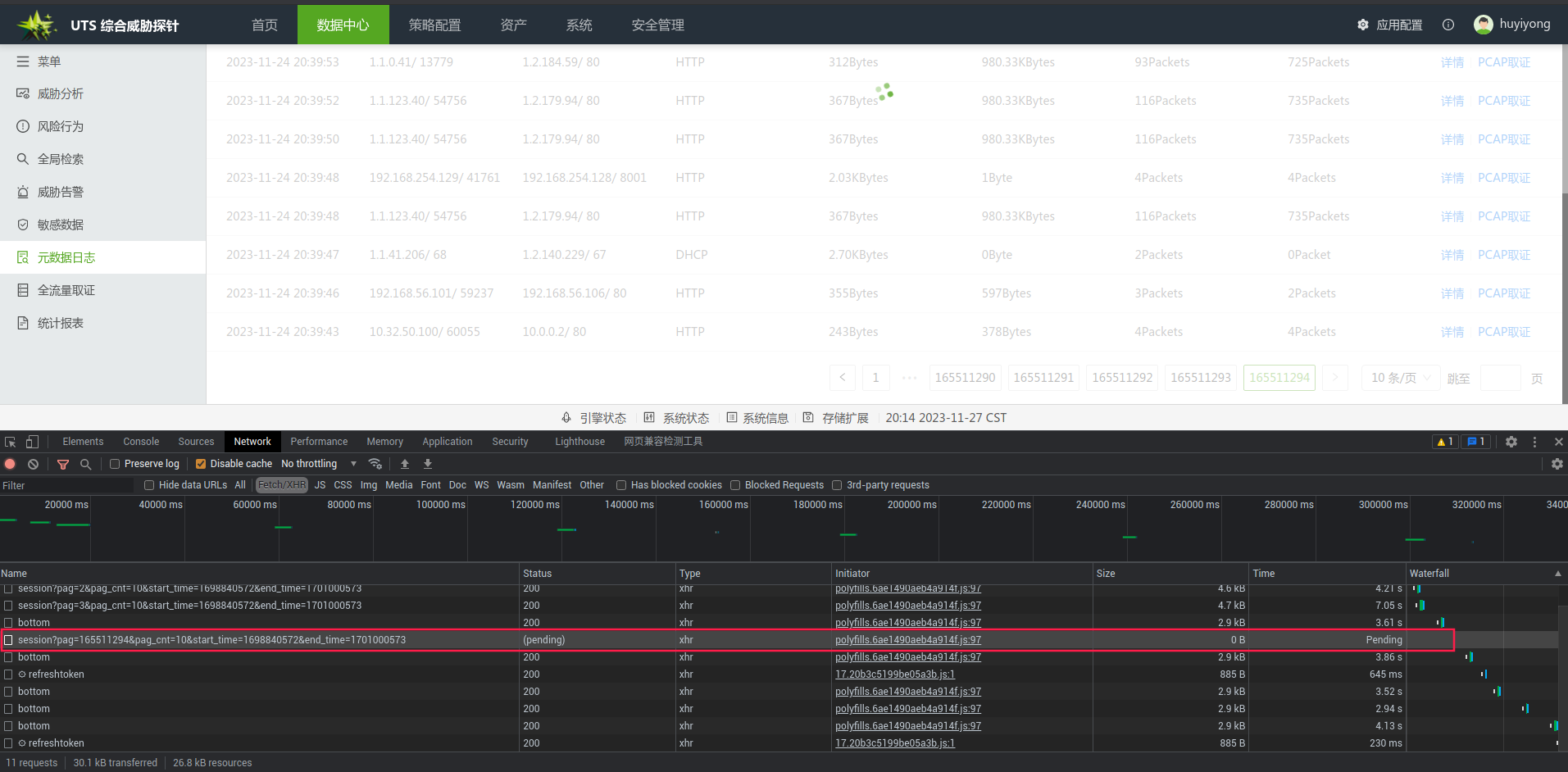
优化后
前三页的响应结果
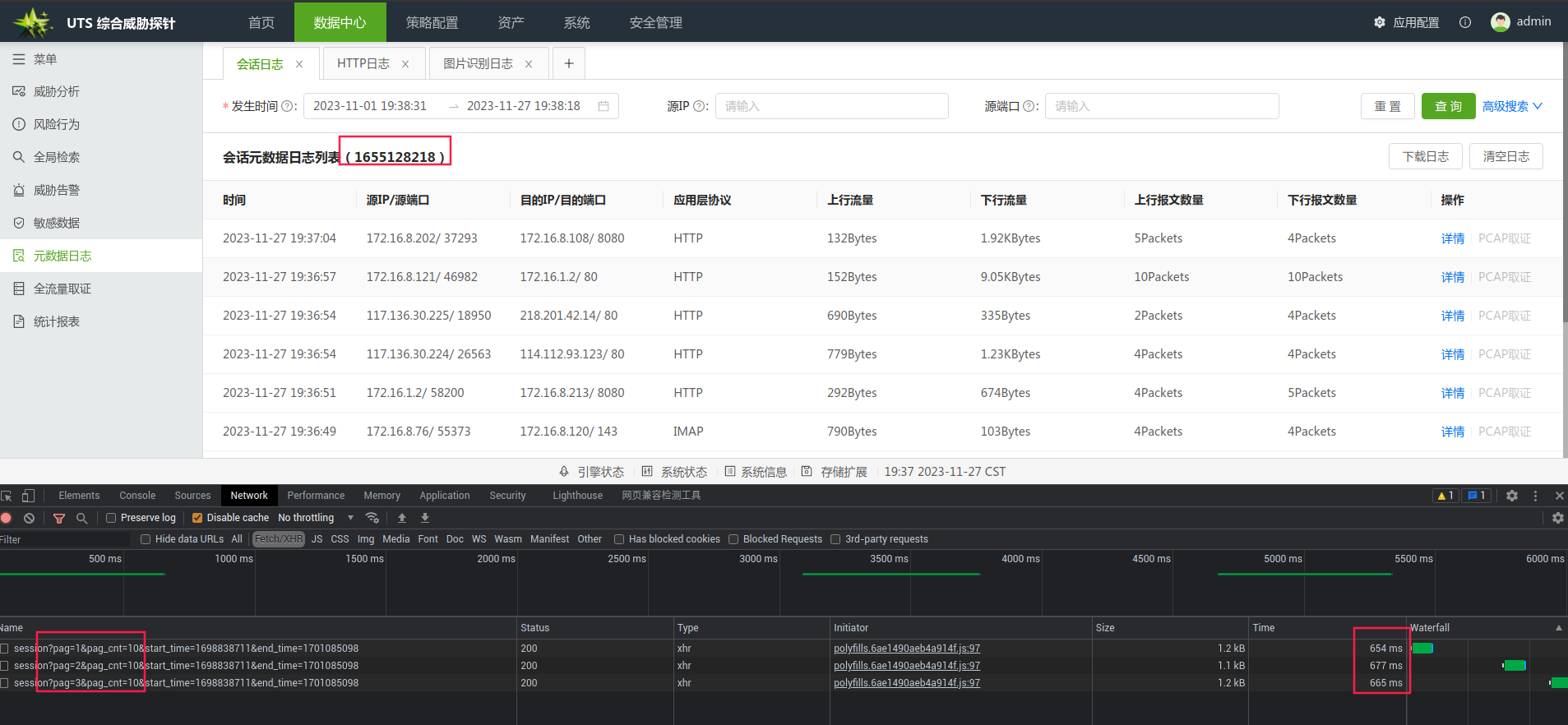
最后三页的响应结果
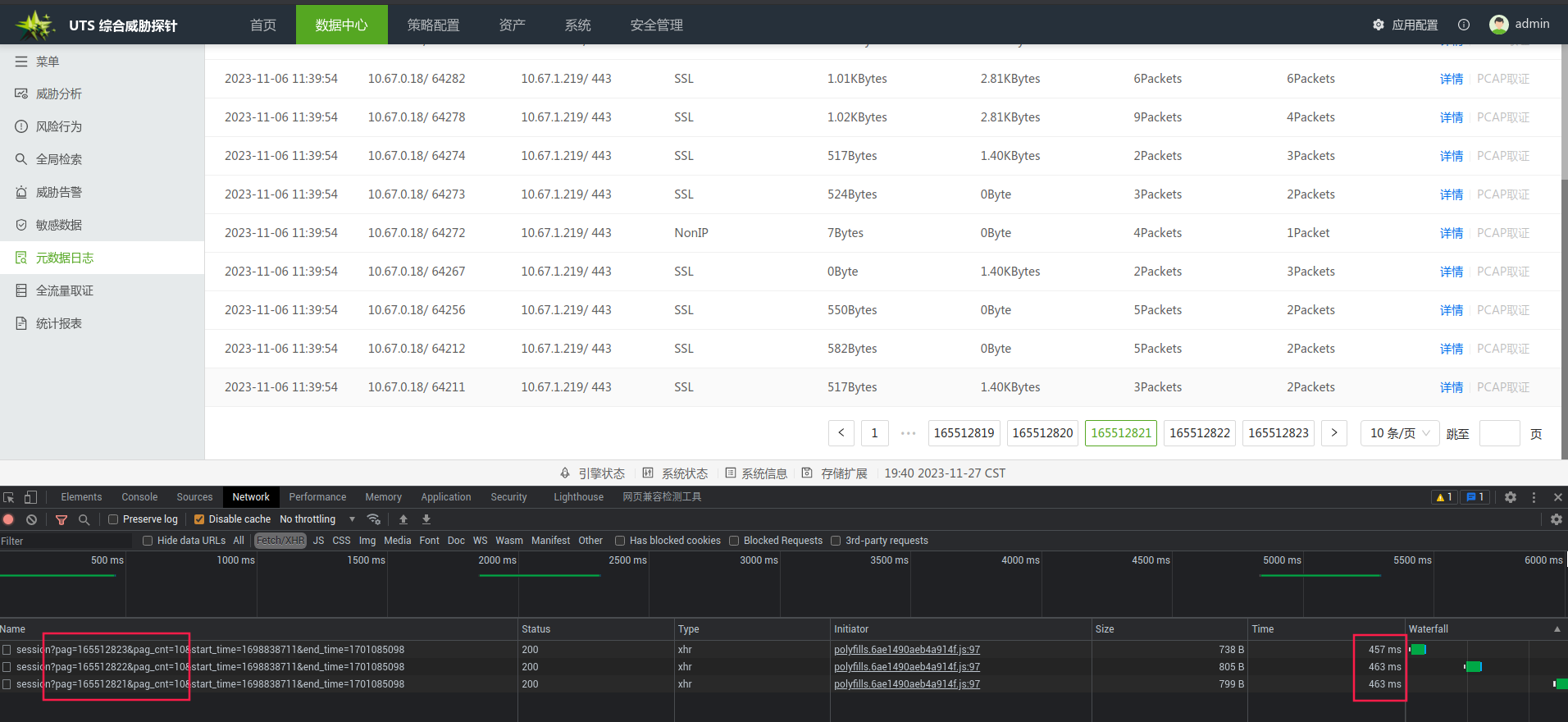
场景2:带条件查询
查询条件为前三个方向的数据,总共将近4个亿的数据量
优化前
前三页的响应结果
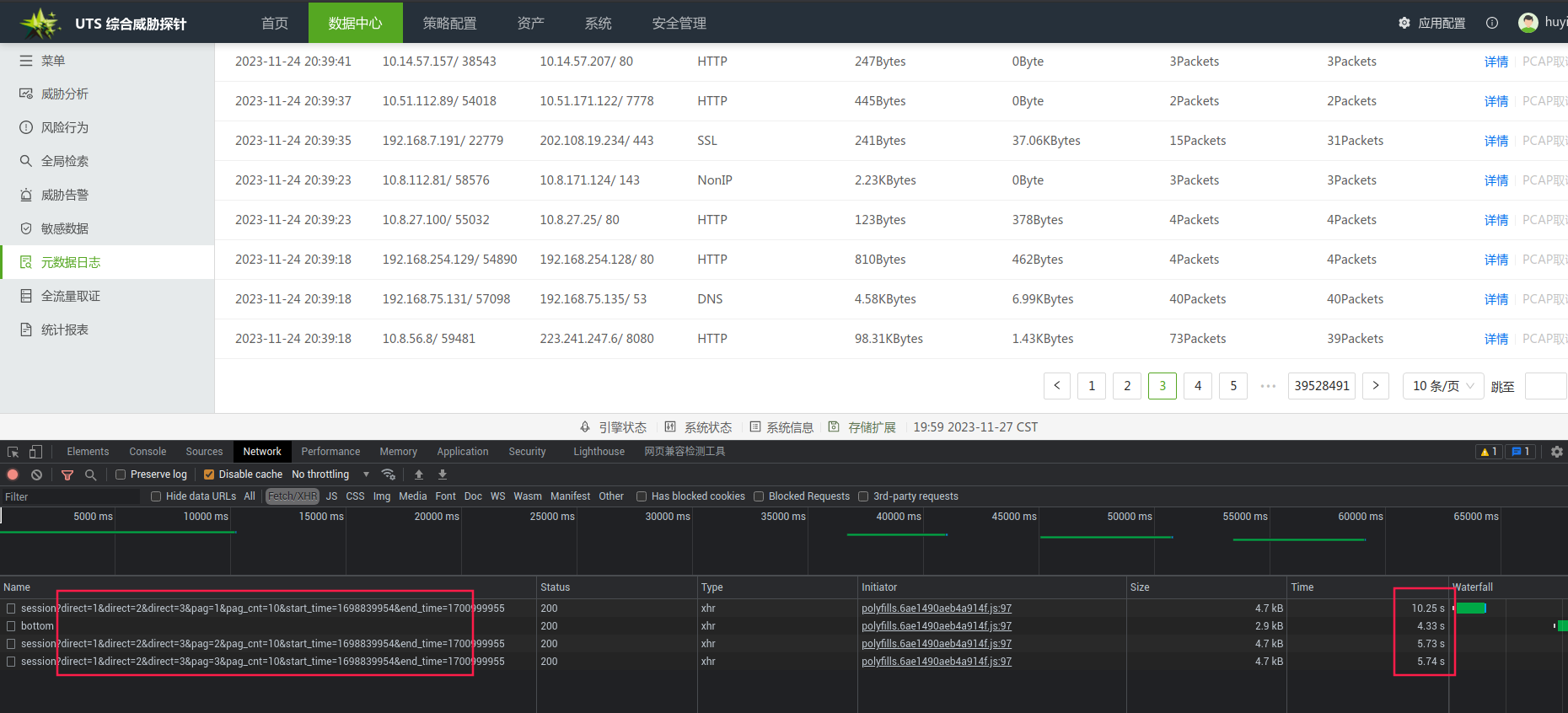
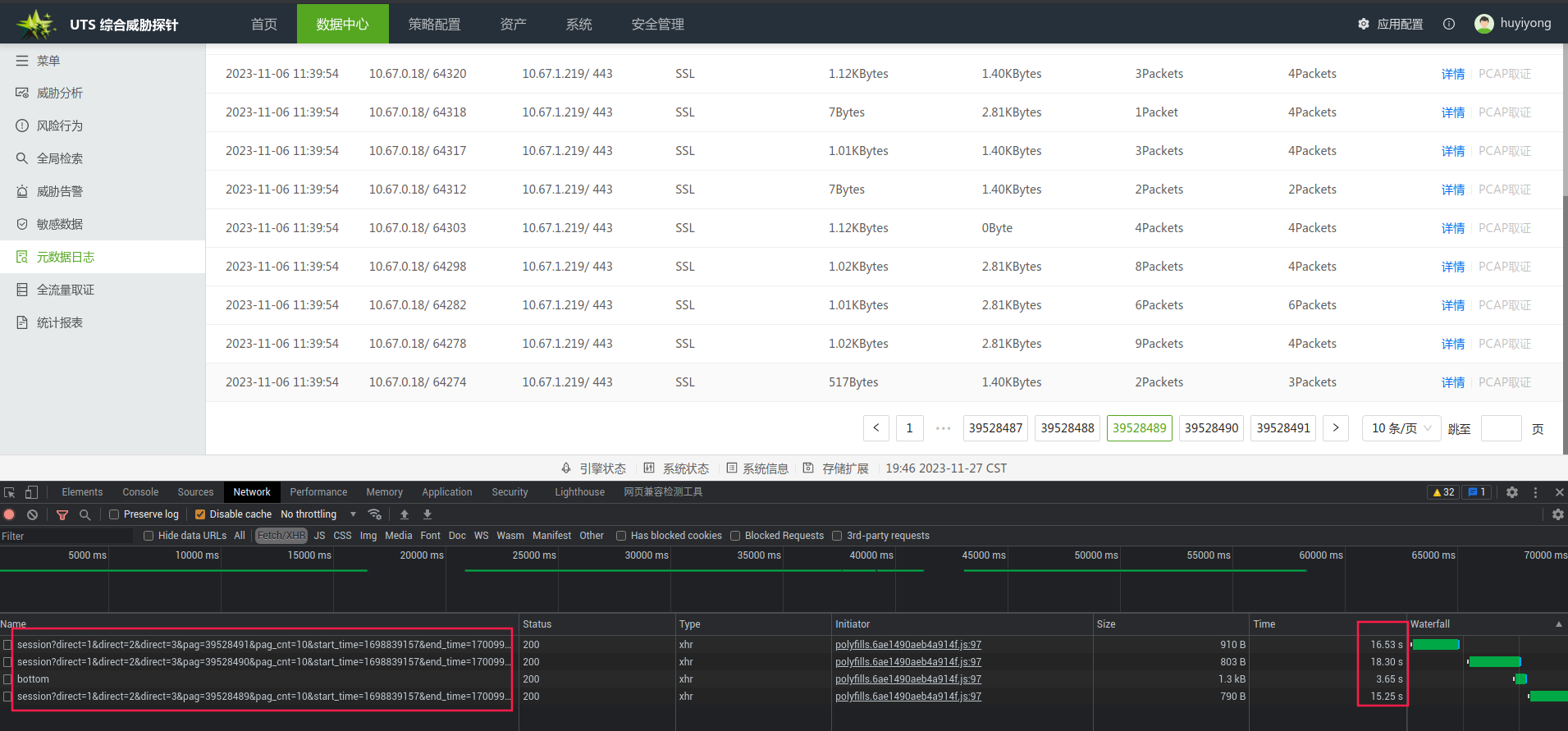
后三页的响应结果:等待了6分钟没有获取到结果,最后被放弃了这个查询。几乎不可能查询
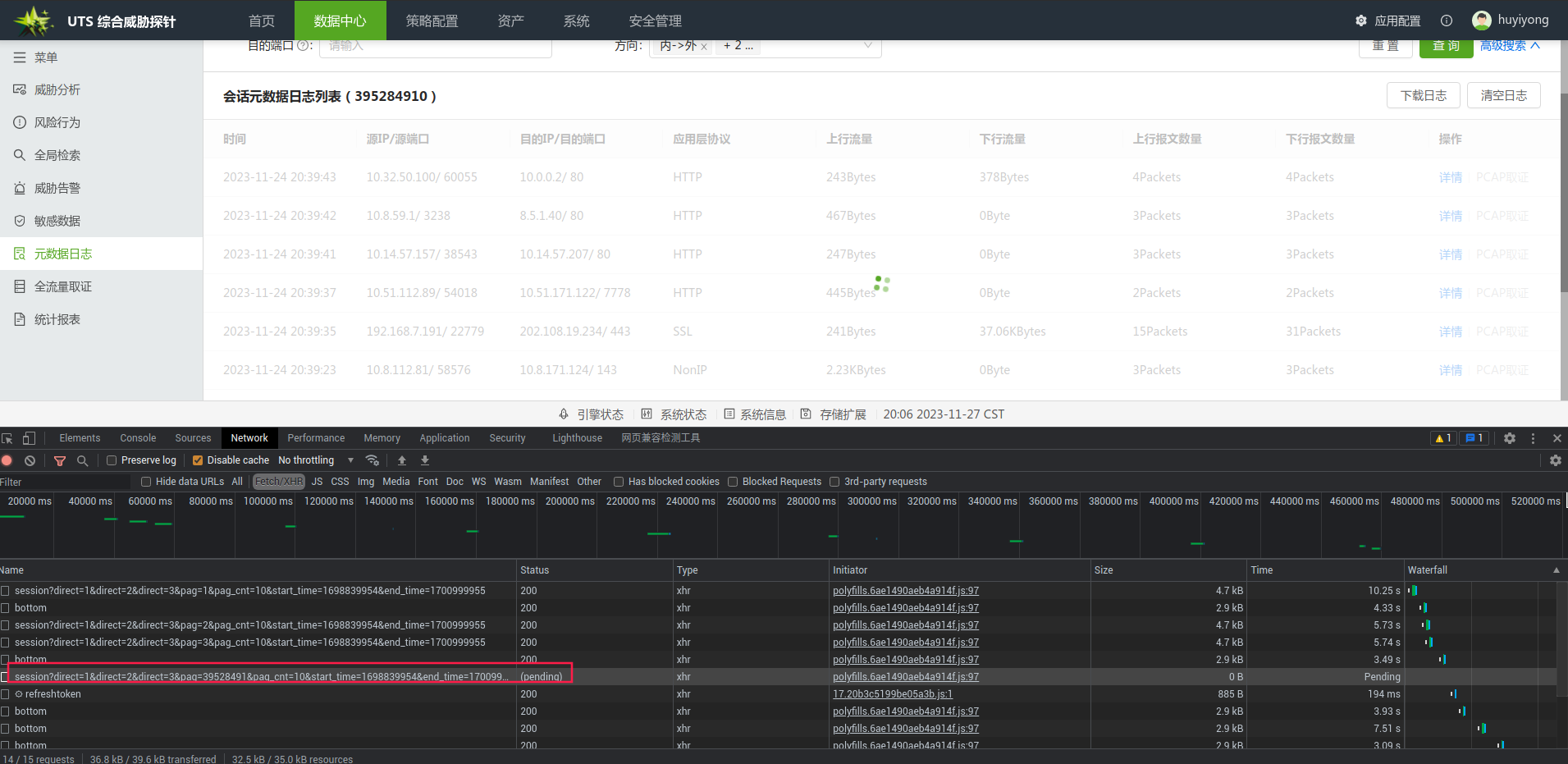
优化后
前三页的响应结果
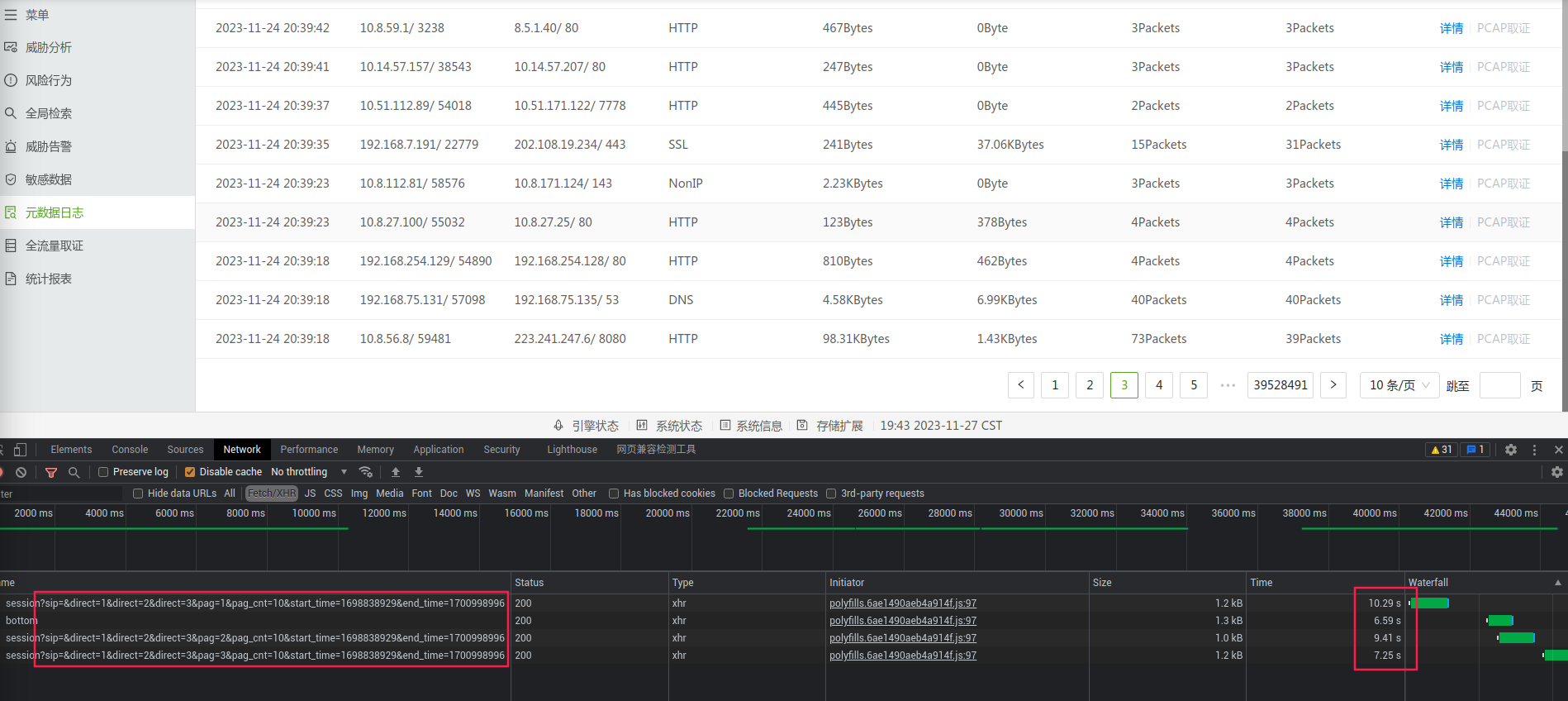
后三页的响应结果
总结
下图为针对场景1的优化前和优化后的效果对比,我们假设最大等待时间为30秒。
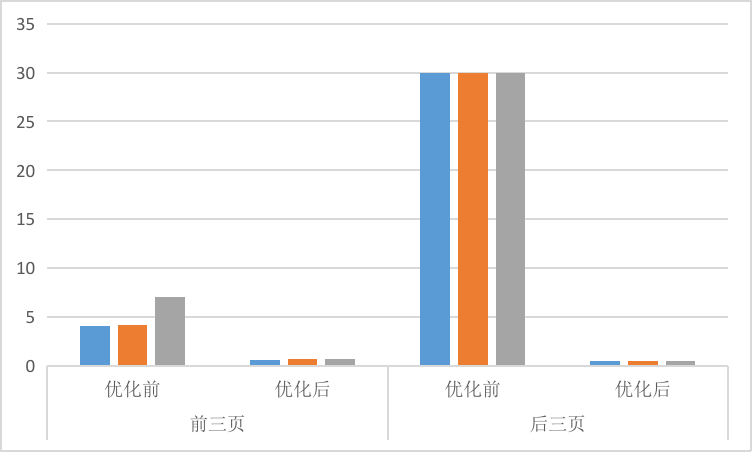
由于我们对默认条件的页面的count做了物化视图的优化,在查询count时,会非常的高效,最后在前三页和最后三页的表现基本一致,响应均在600ms左右。而没有优化前,前三页的响应进本在3秒以上,后三页,基本查询不出来,导致页面一直在转圈,这已经严重影响到用户的体验。
下图为针对场景2的优化前和优化后的效果对比,我们假设最大等待时间为100秒。
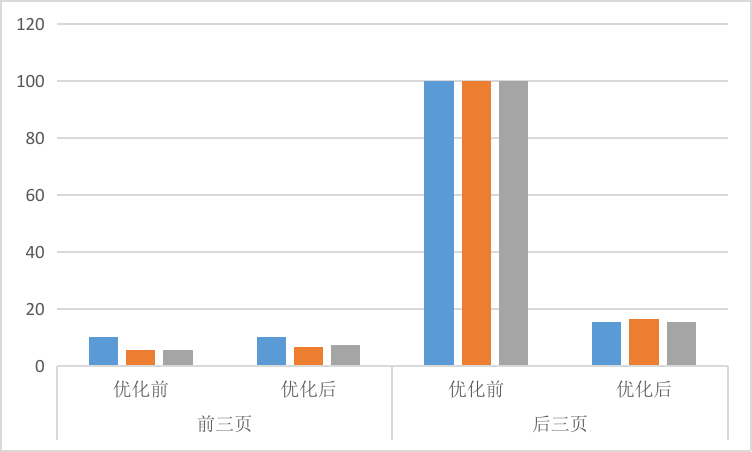
在物化视图中,我们只对默认条件进行了优化,而其它高级查询条件,并没有对齐进行优化。尽管如此,我们在带有查询条件,在后三页的表现也是相当惊人的,基本保持在20秒以内。这是因为尽管count没有被物化视图优化,但在进行时间放缩时,已经将子查询中的数据集合缩小了,从而将总体查询时间拉平。